Presales and marketing teams often lose valuable hours searching for the right slide, case study, or win theme, long before a bid even begins. This case study shows how DataArt accelerated asset discovery by 12x, cut lookup time by 80%, and gave more than 500 users instant, self-service access to over 10,000 curated documents by deploying a centralized, AI-powered presales enablement hub, transforming fragmented repositories into a brand-consistent source of truth.
Challenges
- Self-service gap: DataArt sales and presales teams had no central knowledge base. They depended on colleagues and disparate repositories for key assets, slowing deal cycles and eroding quality.
- Marketing capacity crunch: Because every presales effort has unique requirements, materials search support requests far outpaced available resources, forcing marketers to juggle urgent tasks instead of focusing on research, content creation, and deal-specific tailoring.
- Limited insight into return on effort: Without usage or impact metrics, leadership could not gauge the value of presales support or optimize investment.
- Fragmented repositories: 10,000 assets were scattered across websites, knowledge bases, SharePoint folders, and other libraries, forcing teams to forage manually with no guarantee of freshness or compliance.
- Brand inconsistency: Disparate templates, styles, and visuals crept into proposals, diluting DataArt’s voice and risking mixed client perceptions.
Solution
- To bring speed and consistency, DataArt built Presales Hub, an AI-powered presales enablement hub that unifies content across systems in a single, searchable ecosystem.
- Users leverage Presales Hub as a single source of truth to instantly search across more than five sources and over 10,000 documents in different formats, including the company's websites, knowledge bases, and marketing asset libraries.
- Presales Hub provides a performance-driven toolkit with AI-augmented multi-format search and in-depth results, including summarization, relevance score and explanation, intuitive result filtering options, legal status disclosure, and the ability to export, save, and share asset collections.
- The application acts as a central gateway that preserves domain ownership and enables insights to flow freely across the enterprise. This frictionless self-service experience eliminates the need to wait on other teams. Users can instantly access the assets and insights they need at any time and without delays, helping accelerate decisions, improve consistency, and boost productivity.
Key Outcomes
Solution Highlights
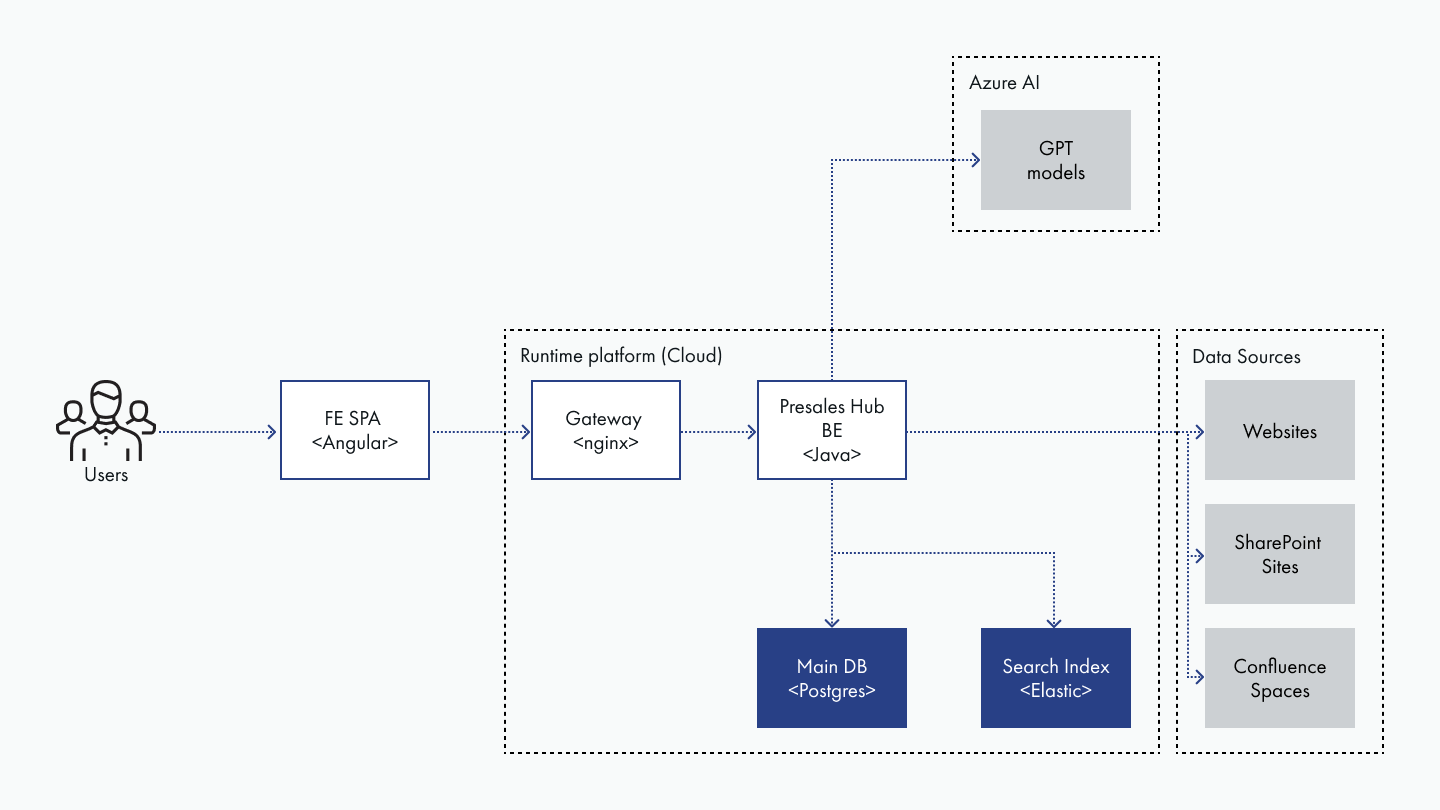
Figure 1: How Presales Hub Turns Scattered Content into Instant Answers
The internal GenAI Search Tool transforms access to company knowledge. The system is specifically built for enterprise presales needs, focusing on delivering specific, actionable documents (such as slides, guides, or reports) rather than just text snippets. It is designed to efficiently handle queries that may yield hundreds of relevant results, allowing users to explore comprehensive sets of artifacts (unlike traditional RAG approach).
Source documents are LLM-enriched and stored in three specialized indexes. User queries are expanded before initiating a multi-faceted search. Results are then intelligently processed, ranked, and explained by an LLM, with features supporting key enterprise workflows.
- Intelligent Document Processing & Indexing: Source documents are first standardized (e.g., to markdown) and then deeply enriched by an LLM. This includes adding audience-specific summaries, detailed metadata (like legal status, industry, or geography), and generating potential user questions the document could answer. This enhanced data is then stored across three distinct types of indexes – tsvector for lexical matching, BM25 for keyword importance, and semantic vectors for meaning-based understanding.
- Advanced Query Understanding & Multi-Vector Search: When a user submits a query, LLM identifies the core intent, generates relevant synonyms, suggests related document titles (HyDE), and creates alternative phrasings of the original request. Then 40-50 parallel searches are launched across all available indexes. This allows to find the best matches, even when keywords from the query are quite different from those in the source documents.
- Sophisticated Ranking by GPT-4o: The numerous initial search results are fused and deduplicated. From this, a top set of candidates (typically 30 to 200 documents) is selected. These candidates are then ranked by an LLM, which decides if they are relevant against the initial user query – and only the good matches are shown to the user. For each document presented, the LLM also explains why and to what degree it is relevant: a key factor in fostering user trust and adoption.
- Enterprise Workflow Integration: It also directly supports user workflows through integrated features like presales-specific filtering parameters, the ability to create and manage document collections, tools for assembling slide decks from search results, and options for easily sharing various result views with colleagues.
- System Resilience: To ensure business continuity, especially in case of LLM service disruptions, robust fallback mechanisms are in place: a standard keyword search mode (fast, free, and covering all repositories in one place) and a manual navigation mode allowing users to browse the knowledge base hierarchy directly through an explorer-like interface.
Current Development Projects
Additional enhancements to Presales Hub under development for DataArt include:
- Transitioning the Presales Hub from search to creation, using cutting-edge summarization models to transform raw context into polished narratives and auto-generated slide decks in minutes.
- A cascade agent workflow will handle diverse query phrasings through a sequential decision-making process. The agent will first determine whether to provide a synthesized answer, retrieve specific documents, or optimize content and source prioritization based on the query's parameters and detected intent. This multi-layered approach will deliver more precise responses to user needs while establishing the foundation for advanced autonomous capabilities.
- Automating case-study production by harvesting project data from account team interviews and internal sources, assembling first-draft collateral, and routing it to marketing for rapid refinement and release.
Conclusion: Unified Presales Acceleration
Presales Hub has reshaped collaboration across DataArt’s five industry practices, twenty R&D labs, and go-to-market teams. By unifying more than five repositories and over 10,000 assets into a single, AI-powered content intelligence hub, every practice can operate with ownership over its content and workflows while the wider organization enjoys a unified knowledge source.
Searches that once involved hours of scavenging now surface clean, on-brand materials in moments, complete with AI-generated context and compliance cues. By drastically reducing time spent on repetitive asset-hunting, teams gain flexibility and bandwidth to focus on creating net-new, customized content that is uniquely tailored for each client and opportunity and that generic AI alone cannot deliver.
The result: 80% fewer ad-hoc requests, rapid user adoption, and a marketing team focused on strategic storytelling rather than routine file retrieval.




